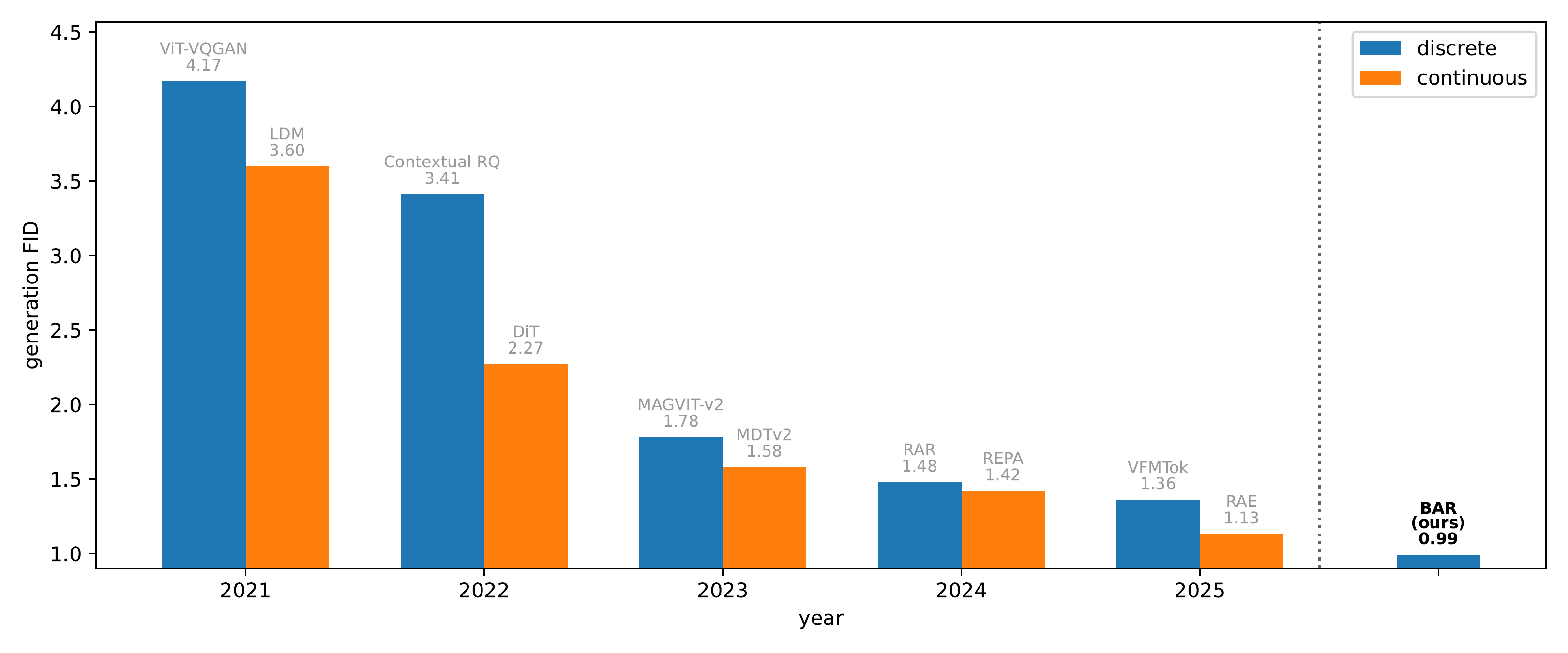
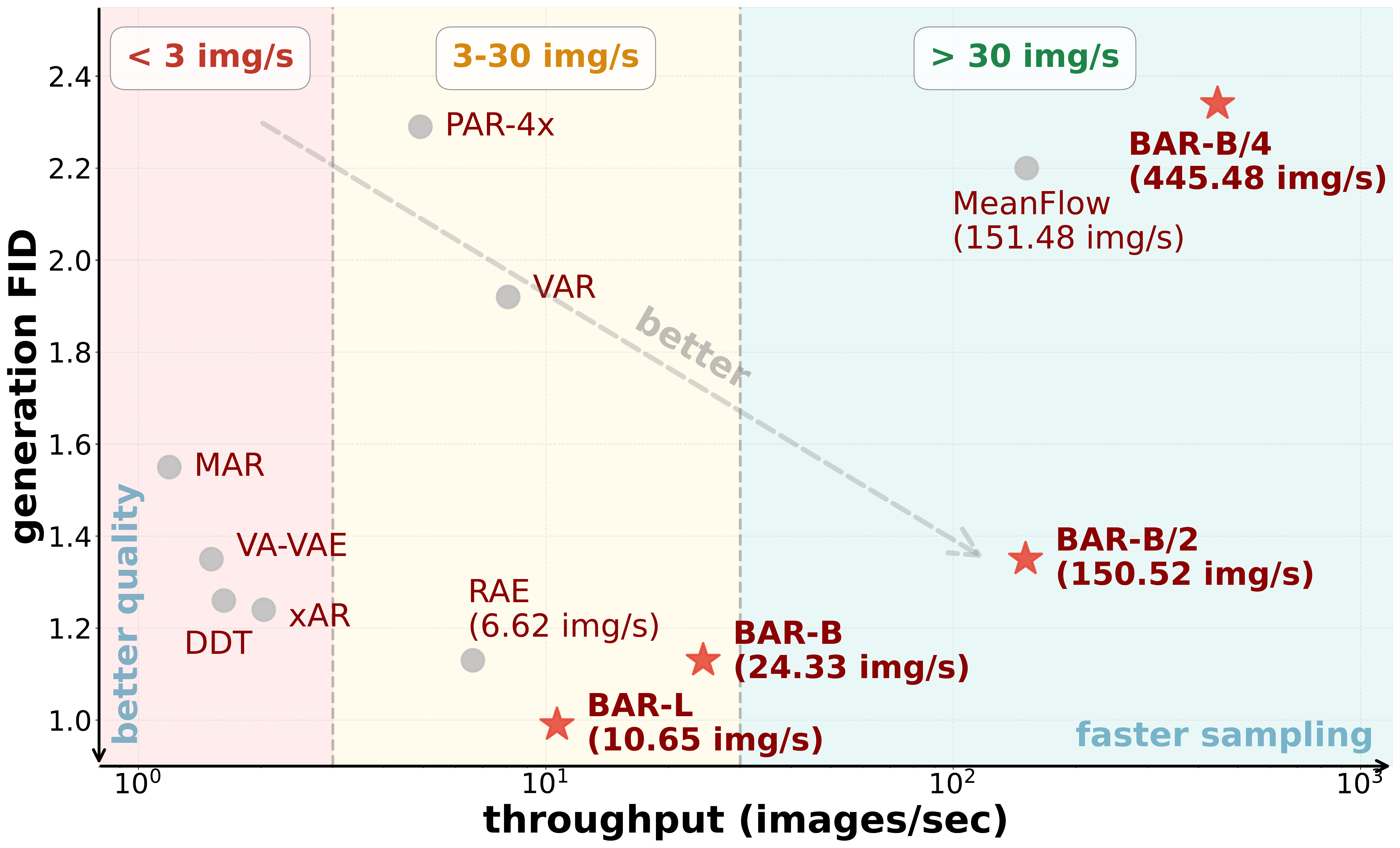
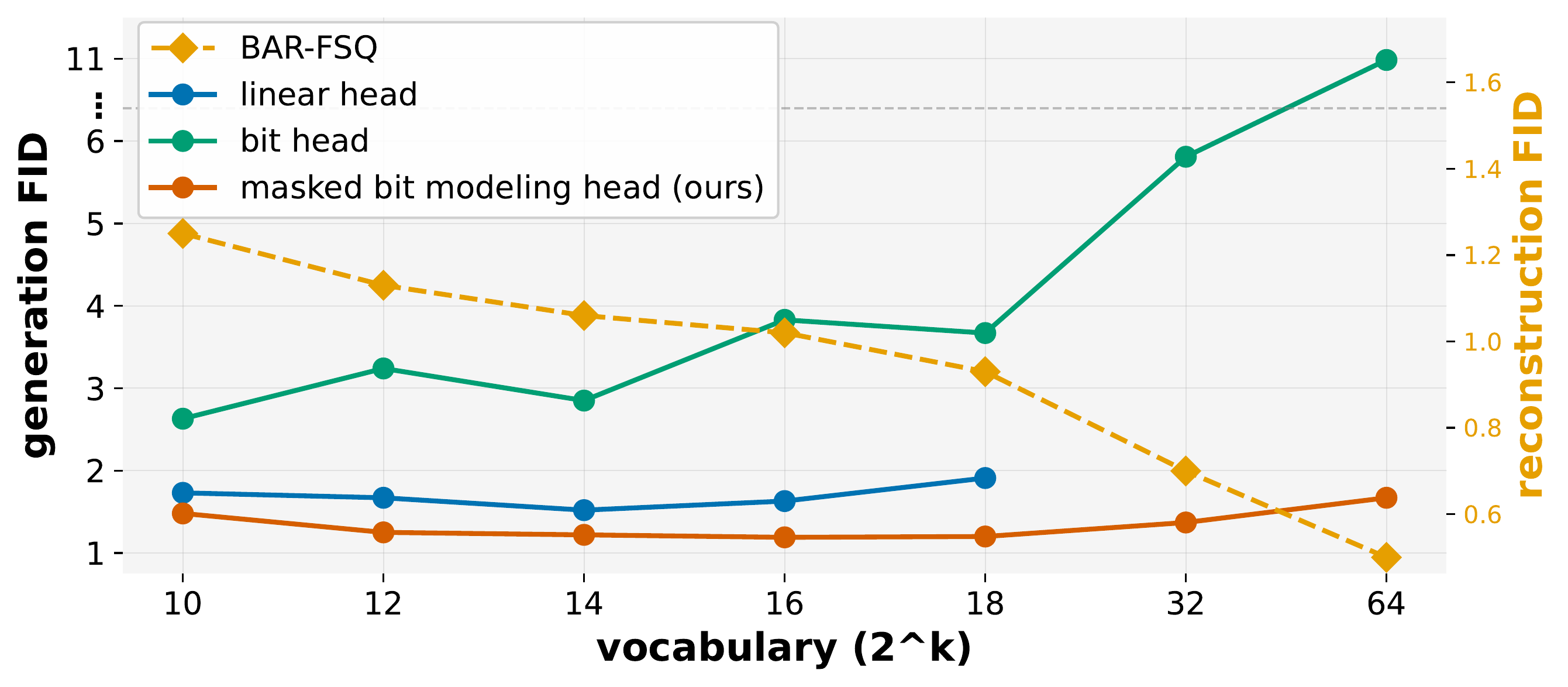
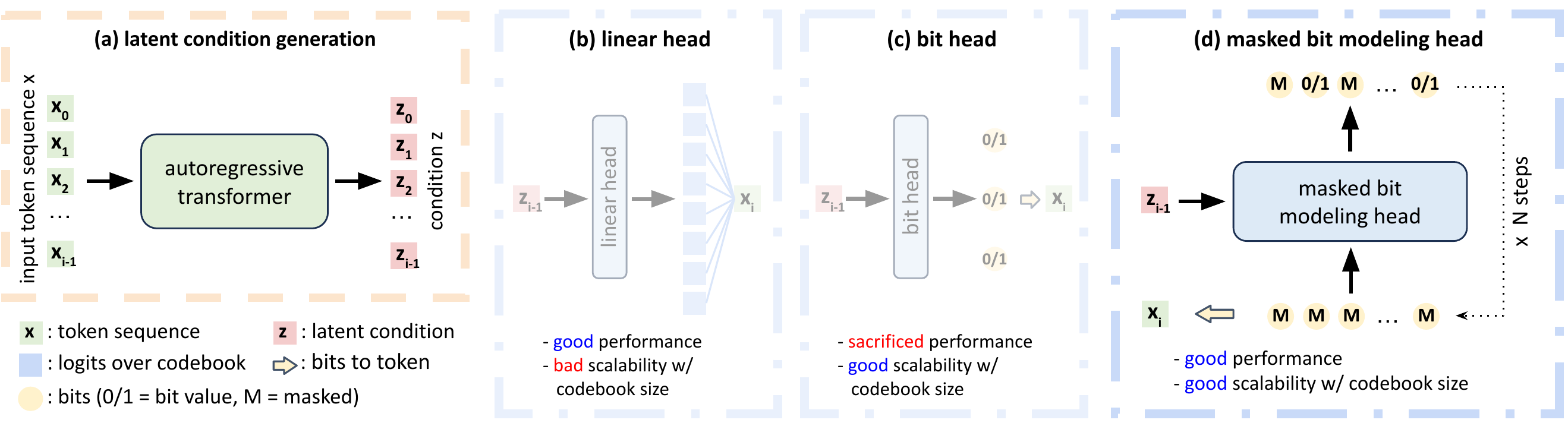
Main Results
ImageNet-256×256 Generation Results
| Method | Type | #Params | FID↓ | IS↑ | Prec.↑ | Rec.↑ |
|---|---|---|---|---|---|---|
| BAR-L (ours) | DiscreteSOTA | 1.1B | 0.99 | 296.9 | 0.77 | 0.69 |
| BAR-B (ours) | DiscreteSOTA | 415M | 1.13 | 289.0 | 0.77 | 0.66 |
| RAE | Continuous | 839M | 1.13 | 262.6 | 0.78 | 0.67 |
| DDT | Continuous | 675M | 1.26 | 310.6 | 0.79 | 0.65 |
| RAR | Discrete | 1.5B | 1.48 | 326.0 | 0.80 | 0.63 |
| MAR | Continuous | 943M | 1.55 | 303.7 | 0.81 | 0.62 |
| VAR | Discrete | 2.0B | 1.92 | 323.1 | 0.82 | 0.59 |
Table: ImageNet-256×256 generation results with classifier-free guidance, sorted by FID (lower is better). BAR-L achieves state-of-the-art FID of 0.99, while BAR-B matches RAE's performance (FID 1.13) with only 415M parameters (vs. RAE's 839M). Both BAR variants significantly outperform prior discrete methods like RAR (FID 1.48) and VAR (FID 1.92).
ImageNet-512×512 Generation Results
| Method | Type | #Params | FID↓ | IS↑ |
|---|---|---|---|---|
| BAR-L (ours) | DiscreteSOTA | 1.1B | 1.09 | 311.1 |
| RAE | Continuous | 839M | 1.13 | 259.6 |
| DDT | Continuous | 675M | 1.28 | 305.1 |
| RAR | Discrete | 1.5B | 1.66 | 295.7 |
| xAR | Continuous | 608M | 1.70 | 281.5 |
Table: ImageNet-512×512 generation results with classifier-free guidance, sorted by FID (lower is better). BAR-L achieves state-of-the-art FID of 1.09 with 311.1 IS, surpassing all prior methods including RAE (FID 1.13), DDT (FID 1.28), and RAR (FID 1.66). Note: Due to computational constraints, the 512×512 model was trained for only 200 epochs.







